v8引擎编译
v8引擎是一个接收 JavaScript 代码,编译代码然后执行 C++ 程序,编译后的代码可以在多种操作系统、处理器运行
v8引擎主要负责一下工作:
编译和执行JS代码、处理调用栈、内存分配、垃圾的回收
v8 编译组成
解析器(parser) 解析器负责将 JS 代码解析成抽象语法树 AST
解释器(interpreter) 解释器负责将AST解析成字节码 bytecode,同时解释器也有直接执行 bytecode 的能力
编译器(compiler) 编译器负责编译出运行更高效率的机器代码
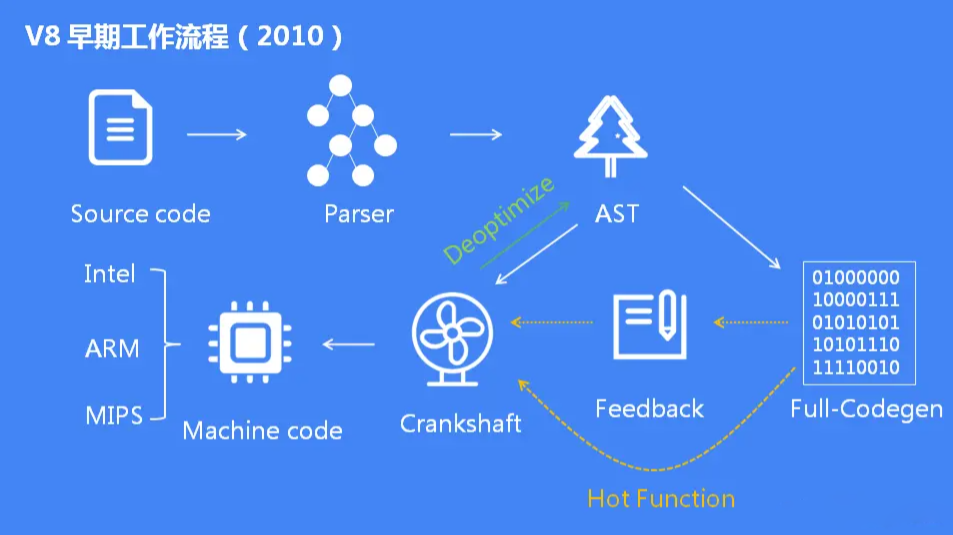
v8 早期架构
v8 早器没有解释器,只有两个编译器
工作流程
JS 代码由解析器生成 AST 抽象语法树,然后由 Full-codegen 编译器使用 AST 来编译出机器代码
当执行一定时间后,V8的分析线器线程收集足够的数据来帮助另一个编译器 Crankshaft 来做代码优化,将需要优化的代码重新解析生成 AST,Crankshaft 使用新的 AST 生成优化后的机器代码来提升运行效率
- Full-codegen 被称为基准编译器,生成为被优化的机器代码,没有字节码产生
- crankshaft 被称为优化编译器
缺点:
- 生成的机器码占用大量内存,对于早起低内存设备影响很大
- 缺少中间层机器码,无法实现一些优化策略,导致 v8 性能提升缓慢
- 之前的编译器无法很好的支持和优化 JS 新语法特性
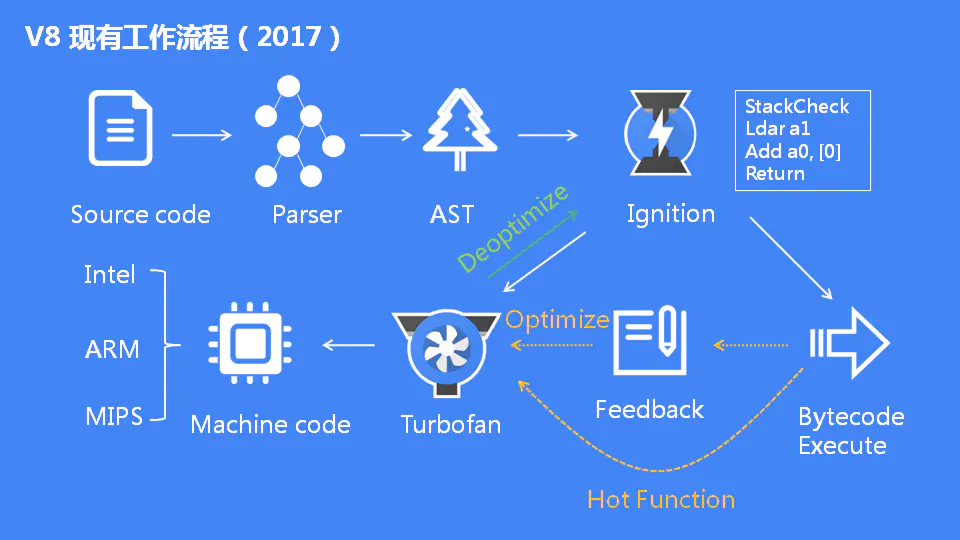
v8 现有架构
解析器、解释器(Ignition)、编译器(TurboFan) 新增字节码作为中间层
工作流程
JS 代码由解析器生成 AST 抽象语法树,然后由 Ignition 基准解释器生成 bytecode 字节码并释放 AST,在代码不断运行过程中解释器收集到很多优化信息,将优化信息发送给新的编译器 TurboFan 编译出经过优化的机器代码,字节码和机器代码共存
优化策略
- 函数被声明,但是没有被调用,该函数不会解析生成 AST
- 如果函数只被调用一次,
Ignition生成字节码后就直接被解释执行,TurboFan不会对其进行优化编译(TurboFan 编译优化的代码,执行次数 > 1) - 如果函数执行多次,函数可能被标记为热点函数,
TruboFan会将热点函数编译为优化后的机器码 - 优化后的机器代码会被逆向还原成字节码,这个过程叫做
deoptimization,这是因为 JS 是动态类型语言,会导致Ignition收集到信息是“错误” 的
function sum(x, y) {
return x + y
}function sum(x, y) {
return x + y
}TIP
触发 deoptimization
一开始,JS 引擎并不知道到参数 x、y 的类型,在多次调用过程中,sum 被标记为热点函数,如果始终都传入 Number 类型,解释器将收集到的类型信息和函数对应的字节码发送给 TruboFan 于是生成优化后的机器代码参数 x、y的类型被假定为 Number。但当调用 sum 函数传入参数不是 Number 类型时,deoptimization 就会被触发,回退到字节码由解释器来解释执行
字节码优点
- 字节码更加简洁,生成的 bytecode 的大小相当于等效的机器码 25% ~ 50% 左右
- 字节码生成速度远远大于机器码,网页初始化解析执行 JS 时间缩短,网页更快的 onlead
- 生成优化机器码不需要从 AST 重新编译,而是使用机器码,
deoptimization也只需要回退到中间层bytecode